
Sentiment Analysis using Doc2PC
Sentiment Analysis is the process of classifying the News/Text document as negative, slightly negative, neutral, slightly positive and positive. Sentiment analysis is based on advanced Natural language processing and Machine Learning Algorithms. It can also be used to classify type of news like Market, Financial or General News. It is based on NLP, Word2Vec & Machine leaning Algorithm. Text cleaning and using different RegEx and NLP is necessary part of sentiment analysis. It can also extract sentiment score of News / Text document. Word2Vec takes as its input large corpus of text and produce vector space, typically several hundred dimensions Word vectors are positioned in a vector space such that words that share common contexts in the corpus are located in close proximity to one another in space. For Word2Vec used, we can use unigram, bigram and trigram after cleaning of text like removing stop words, URL, lemmatization etc. The Word2Vec algorithm includes skip-gram and CBOW models.
Doc2Vec modifies the word2vec algorithm to unsupervised learning of continuous representations for larger blocks of text, such as sentences, paragraphs or entire documents. Both Word2Vec and Doc2Vec can be used for sentiment analysis.
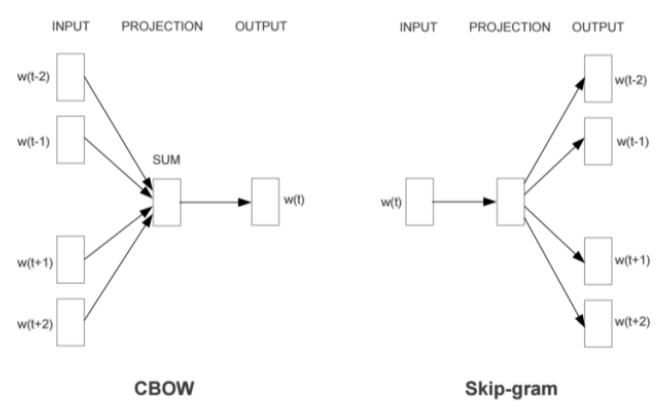
G-Square uses Doc2PC, slightly same approach like Doc2Vec and Word2Vec. We have used 2.5 million untagged news and approximately 8k tagged data. Unigram, Bigrams and Trigrams are used to make vectors after cleaning of text like removing stop words, URL, lemmatization etc. Some dimension reduction techniques are used to minimize several hundred dimensions of word vectors and used it as Principle Components. Now, applied models created on 2.5 million news on 8k tagged data to create PC’s. Using Machine learning algorithms developed sentiment model with 89%. Sentiment models also uses incremental learning algorithm to improve performance of model.
Follow