Text analytics through Natural Language Processing (NLP)
“Computers are incredibly fast, accurate and stupid; humans are incredibly slow, inaccurate
and brilliant; together they are powerful beyond imagination.”
Data science and analytics has become imperative for every organization of every industry in the recent years. But not all data is in the structured tabular format that everybody loves to work on. There exists unstructured data in the form of audio, video and text form.
Text data can be in the form of Word documents, email messages, survey responses, user reviews and social media posts and comments. This is where Natural Language Processing comes to our rescue.
Let’s start with its Wikipedia definition:
Natural language processing (NLP) is an area of computer science and artificial intelligence concerned with the interactions between computers and human (natural) languages, in particular how to program computers to process and analyze large amounts of natural language data. So, Natural language is just a (not so) technical word for the medium through which we humans have evolved to communicate with each other. It may be through audio, video or text. Our focus in this article will be on Natural Language Processing of Textual data.
First and most important part of text analytics is text cleansing.
Text cleaning and preprocessing methods:
Data cleansing and pre-processing takes up approximately 70% of a data scientist time in a given analytics project, especially when it comes to unstructured data like text.
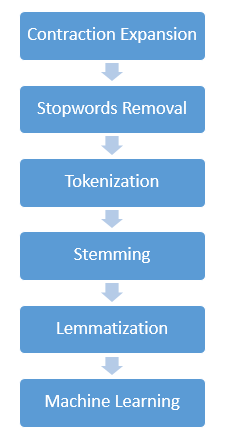
Textual data is particularly messy to deal with and its manipulation methods depends on the type of textual data. But the aim of each method remains the same- converting the unclean and inconsistent data to clean and consistent data. Below are the few operations that are generally performed on textual data:
1. Contraction Expansion:
This method involves conversion of words like “won’t” and “wouldn’t” to “will not” and “would not”. This needs to be done because negation words are hidden inside contraction words which needs to be expanded so that the machine understands negative sentiments.
2. Stopwords removal:
Stopwords are words like “it”, “am”, “are”, “is” exist in a text.
While such words are important to make text comprehendible for humans, these are of no real importance for the machine since they carry negligible information value within them.
3. Tokenization:
Tokenization is the task of chopping the text document up into minimal meaningful pieces which are called tokens. Certain characters like punctuation marks are filtered out during this process.
4. Stemming:
Stemming usually refers to a crude heuristic process that chops off the ends of words in the hope of achieving this goal correctly most of the time, and often includes the removal of derivational affixes.
5. Lemmatization:
Lemmatization, unlike stemming, takes into consideration the morphological roots of the words to remove inflectional endings only and to return the base or dictionary form of a word, which is known as the lemma. It is necessary to have detailed dictionaries which the algorithm can look through to link the form back to its lemma.
6. Machine Learning: Last step is applying Machine learning models on the cleansed and processed data which reveals actionable insights and useful predictions.