
Analytics-based collection models help banks and NBFCs recover loans more efficiently. A collection model helps a bank or an NBFC identify groups of customers where the collection efforts need to be focused on. Many collection systems even now are just rigid rule-based setups, which only take in limited amounts of data to make decisions and do not change with dynamic factors such as markets, client behaviour, their actions, repaying patterns, etc. To evaluate, credit or default risk, understanding behavioural patterns as well as actions becomes equally important and all of this is enabled by using as much data about a customer as possible.
That is why, it becomes highly necessary to segment customers into different categories, wherein each category is subjected to different treatments or methods of debt collection, because different kinds of customers react better or worse to different kinds of techniques. Of late, many institutions have used machine learning for this very purpose to great effect.
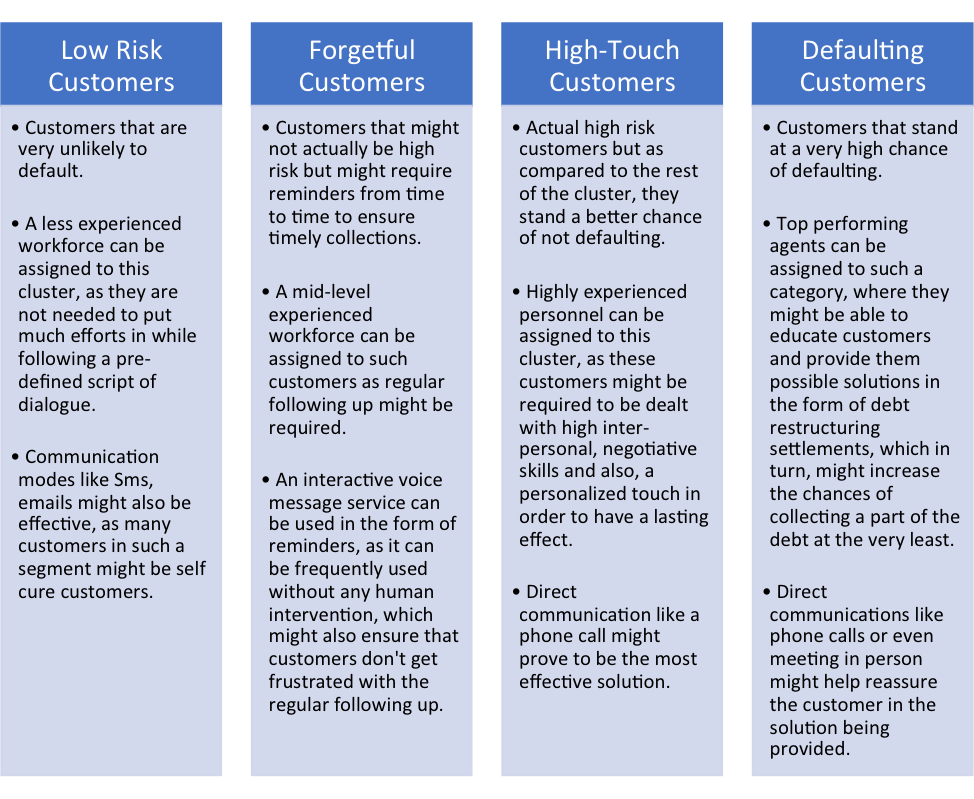
Based on the properties each segment exhibits, a customized solution can be materialized to achieve better results in the form of reduction in the number of defaulters or timely collections. For example, a less experienced workforce can be assigned to customers at low risk of defaulting, because, they might not require a lot of negotiating with, whereas, a highly experienced and skilled workforce with good negotiation or inter-personal skills might help attain better results with customers that have high credit risks. Similarly, different modes of communication can be adopted for different types of customers, which, might help save up on expenses.
One big advantage of segmentation is that, it can help distinguish self-cure customers, who without much effort enable timely collections, from non self-cure customers, where a certain amount of efforts need to be concentrated on, to extract collections. Thus, it certainly helps in effort allocation.
In machine learning, there are various clustering techniques such as K-means clustering, centroid based clustering methods, which use different statistical measures to evaluate similarities in data and thus, based on those similarities, they classify data points into a single cluster and in this way, various clusters with similar data points in them are formed. In the end, through these clusters, patterns in data can be recognized, which can, in turn, help understand data better.
In credit risk, customer segments can be created on their behavioral patterns, buying patterns, buying history, possessions, investments, demographics and many such dynamic factors, that can help lending institutions understand their customers better and act accordingly. An important facet of using computational power and machine learning, is that the whole process can be automated and thus, customers get continually classified into segments and assigned action points. This can help save up on a lot of time as well as manpower, as it helps direct efforts in the right direction, where results can be achieved.
As with everything, there is always a scope of improvement in the model’s performances and that can be achieved by using more and more data as it comes along and also, by using more factors that give more information about a customer. These changes to a model can be easily accommodated as the whole process is automated. All in all, machine learning puts data at its forefront to make decisions and similarly, data is equally important when it comes to understanding customer psychology and behavior. That is why, machine learning can drive customer analytics to great effect.
Follow