
TOPIC MODELLING
One of the interesting aspect of NLP on text mining is Topic Modelling.
Topic modeling is automatically discovering the abstract “topics” that occur in a collection of documents. Quite recently, topic models are being widely used to identify topics in a text corpus.
Below shows a general topography of text in real world data.

Topic modeling can be said as a form of dimensionality reduction. It automatically identifies topics present in a text and derives hidden patterns exhibited by a text corpus, thus assisting better decision making.
Topic Modelling is different from rule-based text mining approaches that use regular expressions or dictionary based keyword searching techniques. It’s an unsupervised approach used for finding and observing the bunch of words (called “topics”) in large clusters of texts.
Topics can be defined as “repeating patterns of co-occurring terms in a corpus”. An ideal topic model should result in – “health”, “doctor”, “patient”, “hospital” for the topic – Healthcare, and “farm”, “crops”, “wheat” for a topic – “Farming”.
Topic Models are very useful for the purpose for document clustering, organizing large blocks of textual data, information retrieval from unstructured text and feature selection. Take for example New York Times who are using topic models to boost their user – article recommendation engines.
The different Topic Modelling algorithms are:
- Latent Semantic Analysis (LSA) which primarily uses the distributional hypothesis and singular value decomposition (SVD)
- Non-Negative Matrix Factorization (NNMF) has an inherent clustering property and uses linear algebra
- Latent Dirichlet Allocation (LDA)
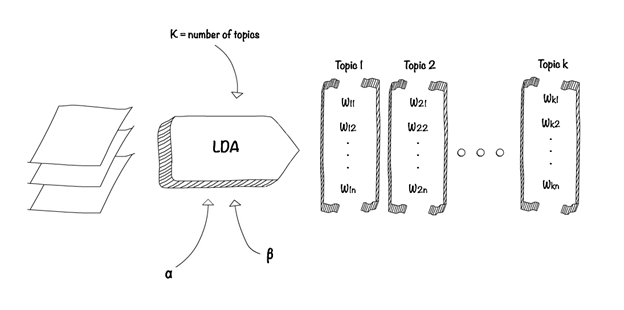
Most widely used algorithm for Topic Modeling is Latent Dirichlet Allocation (LDA).
LDA assumes documents are produced from a mixture of topics. Those topics then generate words based on their probability distribution. Given a dataset of documents, LDA backtracks and tries to figure out what topics would create those documents in the first place.
Python’s gensim library can implement LSA and LDA while we can implement NNMF using Python’s sklearn package.
APPLICATIONS
Let’s look at the applications of NLP now.
Customer reviews and feedback:
Manual analysis of textual data generated from customer reviews and feedback is tiresome and time-consuming. It would be interesting to know the overall sentiment of the customers through their reviews and feedback about a product or service. Intent Analytics along with sentiment and demographic insights provide valuable data for campaigning and sales team.
Social Media posts:
Text analytics on social media posts make us understand the general sentiment or emotion the customers have about a product or service, how the text about the product or service changes over time and intent of the text.
Risk analytics:
Risk Management based on text mining technology can dramatically increase the ability to mitigate the risk that ensures complete management of large databases, and links together information and is able to access the right information at the right time.
Follow