
Text Mining Analytics
Background
The term text analytics describes a set of linguistic, statistical, and machine learning techniques that model and structure the information content of textual sources for business intelligence, exploratory data analysis, research, or investigation.
Text mining is t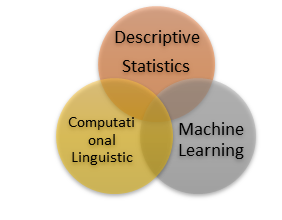 he analysis of data contained in natural language text. Text analytics includes the text mining techniques to solve the business problems.
he analysis of data contained in natural language text. Text analytics includes the text mining techniques to solve the business problems.
Why Text Mining & Analytics?
As per the sources from Wikipedia, 80% of business relevant information originates in unstructured form, primarily Text. To cope with it, business uses Text mining and analytics. Text mining can help an organization derive potentially valuable business insights from text-based content such as news articles, word documents and postings on social media streams like Facebook, Twitter, etc.
Text Mining and Analytics includes various statistical models such as Descriptive Statistics and Inferential Statistics. In Descriptive Statistics, the data is used to provide descriptions of the population, either through numerical calculations, graphs or tables. Inferential Statistics makes inferences and predictions on a sample of data. Computational linguistics is an interdisciplinary field concerned with the statistical or rule-based modeling of natural language from a computational perspective, as well as the study of appropriate computational approaches to linguistic questions. Machine learning is a field of computer science that gives computer systems the ability to “learn” with data, without being explicitly programmed.
Text Mining also plays a major role in Banks and NBFCs in Risk management by mining into the historical and current affairs of its stakeholders and investors via Social media like Facebook, Twitter as well as News articles and getting the analysis of the same, which helps them in making better decisions. Through Text mining, the business users, gets to know the market sentiment of a particular sector, companies or even of an individual through sentiment analysis.
If we take a real world scenario, the news around PNB scam of Nirav Modi or the Simbhaoli Sugars scam in Oriental Bank of Commerce can be tracked at its early stage by the banks through early news coming on web with the help of Text Mining and Analytics.
Types of models
In machine learning, Support Vector Machines(SVMs) are supervised learning models with associated learning algorithms that analyze data used for classification and regression analysis. Given a set of training examples, each marked as belonging to one or the other of two categories, an SVM training algorithm builds a model that assigns new examples to one category or the other, making it a non-probabilistic binary linear classifier.
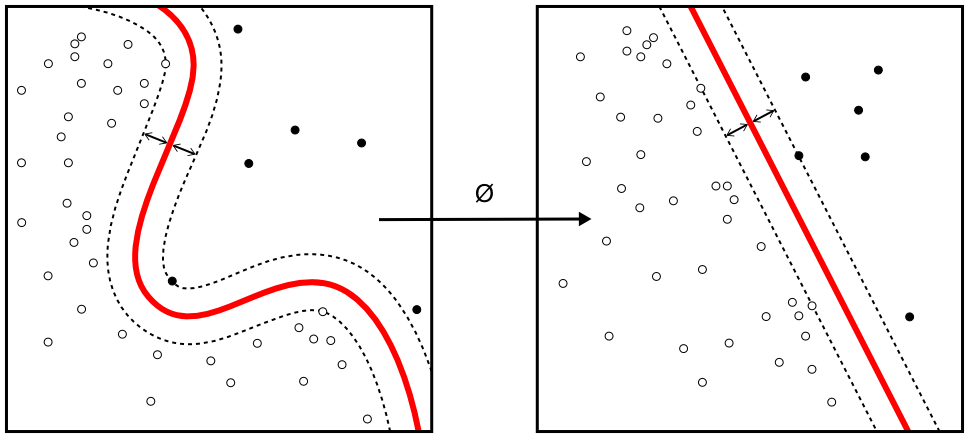
In machine learning, Naive Bayes classifiers are a family of simple probabilistic classifiers based on applying Bayes’ theorem with strong (naive) independence assumptions between the features. Naive Bayes classifiers are highly scalable, requiring a number of parameters linear in the number of variables (features/predictors) in a learning problem. Maximum-likelihood training can be done by evaluating a closed-form expression, which takes linear time, rather than by expensive iterative approximation as used for many other types of classifiers.

Naive Bayes Probabilistic Model
Latent semantic analysis (LSA) is a technique in natural language processing, in particular distributional semantics, of analyzing relationships between a set of documents and the terms they contain by producing a set of concepts related to the documents and terms. LSA assumes that words that are close in meaning will occur in similar pieces of text (the distributional hypothesis).
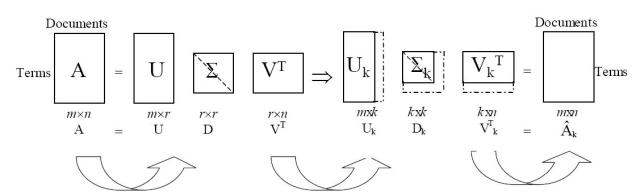
Latent Semantic Analysis Model
In natural language processing, Latent Dirichlet allocation (LDA) is a generative statistical model that allows sets of observations to be explained by unobserved groups that explain why some parts of the data are similar. For example, if observations are words collected into documents, it posits that each document is a mixture of a small number of topics and that each word’s creation is attributable to one of the document’s topics.
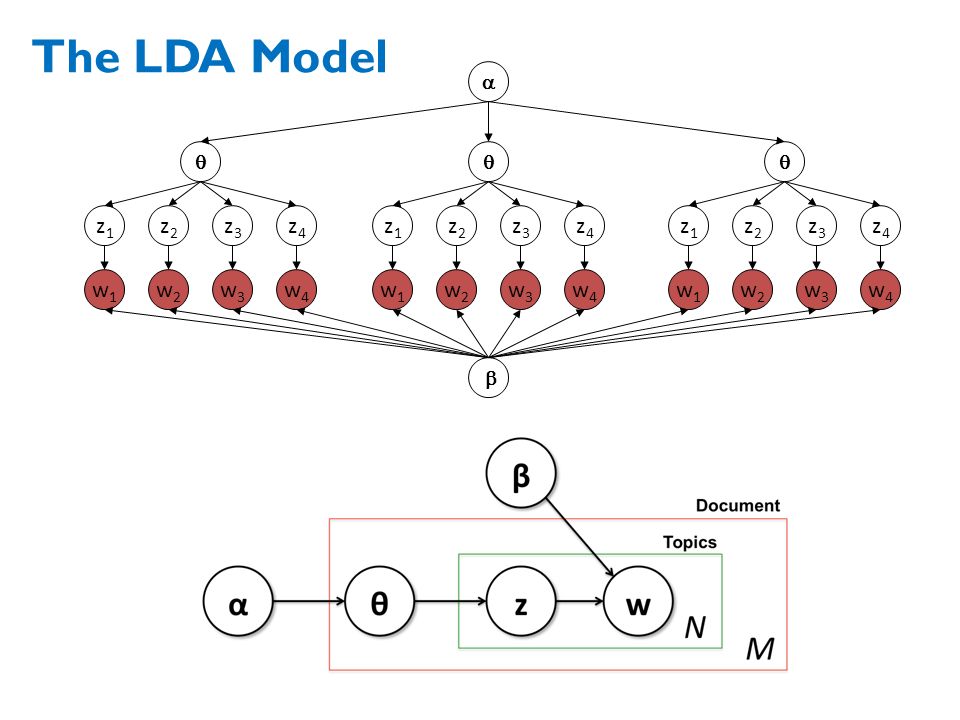
Latent Dirichlet Allocation (LDA) Model
Follow