
News Curation
What is News Curation ?
On the internet, searching for the right kind of news can be a time consuming task simply because sometimes you cannot exactly explain what you are looking for or that the system fails to understand the requirements. But through various tasks like Topic to Keyword conversion, web scraping, news relevance, text summarization, news categorization and sentiment analysis, curating the right kind of news can be made possible just through giving a keyword or a set of keywords.
All of this is encapsulated in a News Curation system, which runs all these tasks in sequence and finds news relevant to the keywords entered in the system. Let’s look in depth as to how these tasks are performed and what can be obtained through each of them.
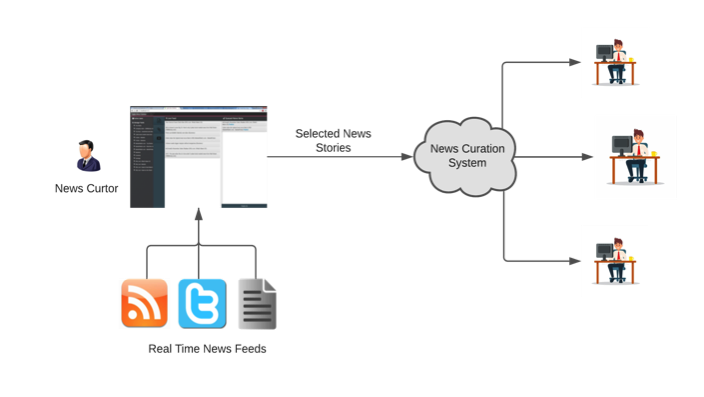
Fig. News Curator
Methods & Algorithms
Topic to keyword extraction is the process of obtaining words relevant or related to the topic entered. Through running generic search queries on search engines and taking the top webpages, a database of news is made. Initially, keywords are extracted from the database through using a graph based TextRank algorithm or using common techniques like TF-IDF, LDA, etc. Before using any of these techniques, text has to be cleaned by removing irrelevant words like stopwords, adjectives and words which have less than 3 letters. Furthermore, words are tokenized to their root forms so that cases of different variations of the same word are eliminated. Such cases can incorrectly influence the methods used.
Through the TextRank algorithm we can compute similarity scores between phrases or sentences and then rank them as per the highest scores. Initially, phrases are converted in their vectorized forms and similarity scores are computed and stored in a matrix. Thus, the top ranked phrases are selected. Similarly, TF-IDF computes importance for a word on the basis of it’s frequency in a sentence and the document. So given a topic, these techniques can be used to extract keywords relevant to that topic.
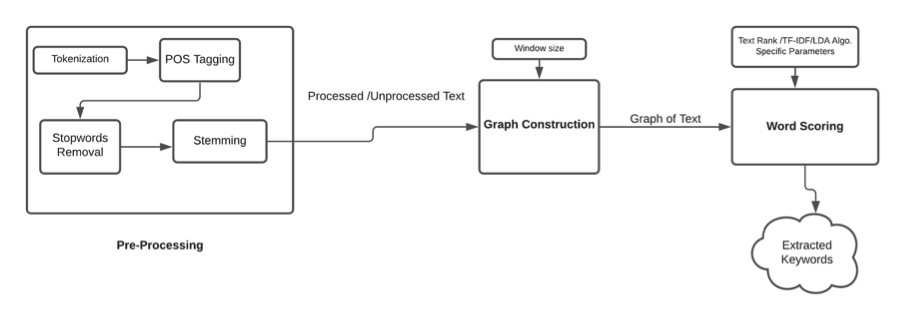
Fig. Sub-Tasks Sequence – Keyword Extraction Methods
Data Extraction
Based on the keywords generated, data from web pages relevant to those keywords is scraped. Scraping can be done through mediums like RSS feeds, third party APIs or even through ethically scraping webpages that allow it. RSS feeds are used to scrape webpages related to generic and broad keywords that cover a whole range of topics, whereas third party APIs are subscription based media that allow scraping from a pool of webpages, where we also have the option to filter for the most recent news. Ethical scraping is done through python libraries like BeautifulSoup, Selenium, Scrapy etc. which convert the HTML of webpages into a very accessible format and through navigating this format we can extract the data we require.
After collecting webpages relevant to the keywords, a further check of relevance is done through an algorithm called BM25. This algorithm employs the Bag of Words technique that computes the frequency of a term, in our case, the keywords, in the webpages and based on that frequency it ranks webpages, with the top ranked webpages having the highest frequencies.
Validation and Summarization
After filtering out the irrelevant webpages, it is important to summarize the content in each of these webpages. Summarization is usually done through adopting a scoring technique and the extracting the sentences with the highest scores or through employing Natural Language Processing, which does not extract sentences but generates an entirely new summary. The latter is a technique that is yet to be developed to a point where it can generate human acceptable summaries. So generally, techniques like TextRank, Latent Semantic Analysis, TF-IDF are used, which are also formed on the basis of scoring sentences as per the frequency of relevant terms in them.
Categorization
Once, the news is prepared, we define categories for each of them. This serves the purpose of aiding keyword extraction in the future. A supervised machine learning model trained on past data consisting of news and their categories is used to label the incoming news. The model is trained on bi-gram or tri-gram keywords extracted from the news through techniques like TF-IDF and their categories.
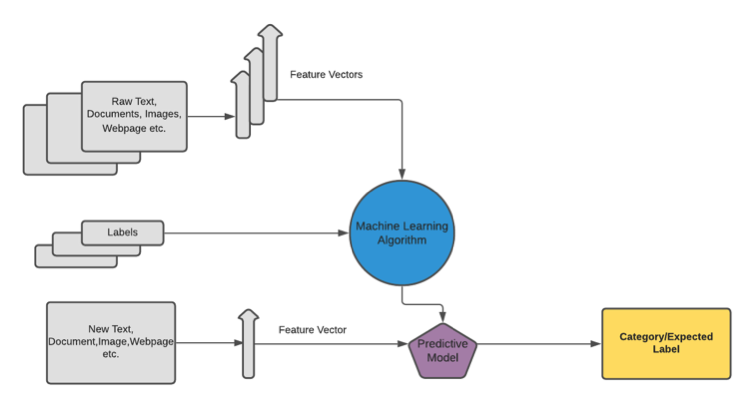
Fig. Categorization using Supervised Machine Learning
Sentiment Analysis
Finally, the sentiment for the news is determined. Predicting the sentiment of text can be done through supervised machine learning Classification models like Logistic Regression, Neural Networks, etc. that get trained on pre-tagged examples converted into their vectorized forms. A customized rules-based model can also be created through using parts of speech tagging and identifying named entities. Parts of speech often follow defined sequences and rules. For example, adjectives and adverbs usually depict emotions whereas nouns and pronouns generally represent named entities which usually have little to no sentimental value. Similarly, adjective-noun combinations like “unacceptable methods”, “amazing view” usually display sentiment. So, by taking certain similar aspects into consideration, customized rules can be created and based on those rules the sentiment can be determined.

Conclusion
These are the various steps that in combination make up a News Curation System.
Follow