
Enhancing Credit Facility Through a ML Model In Credit Cards For a Large Asian Bank
Background:
The client has a credit card facility that allows the credit cardholders of good credit standing to convert a portion of their billed credit card retail balance to instalments. Based on 12 months historical data, the bank wanted to predict who among the qualified cards customers have a highly likelihood to take-up this facility.
Propensity scoring is a common practice in the banking industry. To create this propensity model, we gathered relevant data from the client around credit utilization, delinquency history of the customer, spend behaviour across various categories like F&B, holidays, education, revolving behaviour of the customer, transaction related variables, etc totalling at about 6000 features.
By using data-driven insights, targeted marketing campaigns can be run to credit card customers with high likelihood such as emails, or push notifications. The created model now identifies qualified customers every month with high propensity to avail the credit card product.

Approach:
Outlier handling: Outliers were retained as is since there was no way to determine if they were errors in the data or real outlier values. Additionally, the algorithms we used are robust against outliers.
Missing values: Imputation of missing data records with appropriate values was done after careful statistical analysis.
Feature Elimination: Having a wide dataset of 6000 features, we could not use this for modelling since it will lead to an unnecessarily complex model with poor performance. So, we resorted to feature elimination strategies.
a. We first did a univariate analysis and features with very less variance and large number of missing values were dropped. The thresholds for these were arrived at heuristically.
b. We removed all the constant and quasi constant features (more than 99.5% of the observations show a single value) since they do not add much value to the model.
c. Feature ranking was done based on the correlation of each feature with the target, compensating the correlation ranking based on multicollinearity of each feature with every other feature in the dataset.
d. Ultimately, an improved random forest-based feature selection algorithm and recursive feature elimination left us with 15 most important features towards the target variable.
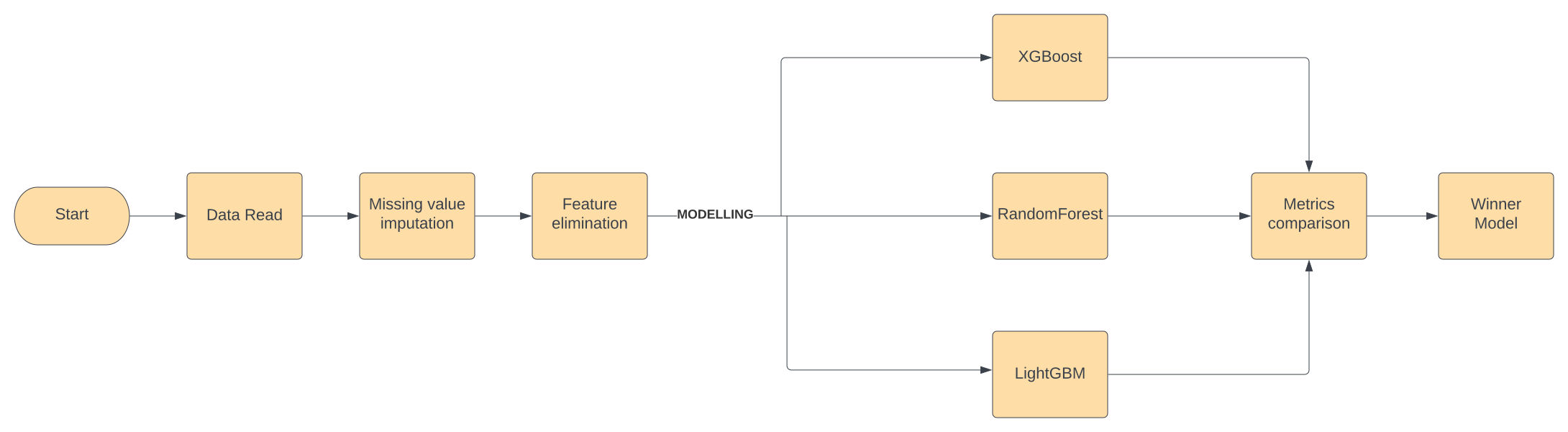
Solution:
We used 3 different algorithms on the above dataset and checked the testing metrics for each of the algorithms to select a winner. These were tree-based models – Random Forest, XGBoost and LightGBM. Blackbox techniques like Artificial Neural Networks were avoided to keep the model from getting complex and heavy for maintenance. Furthermore, the client had clearly stated beforehand that they preferred explainable AI over black box models.
The winner algorithm came out to be LightGBM. It was then finetuned to get the final production ready model with a recall of 90% on the out of time validation dataset. Recall of a model is the ability of the model to not miss out on high value customers, ie, the capture rate.
