
Too many cooks make the broth tastier.
Introduction
Incorrect is the old adage: Too many cooks spoil the broth.
Updated adage in this age of AI and ML: Too many models make the accuracy higher.
Ensemble Learning in Machine Learning is when more than one machine learning algorithms merge to produce a better and more robust decision model, even though individually, they may be weak or average in predictions. Contrary to ordinary machine learning approaches which try to learn one hypothesis from training data, ensemble methods try to construct a set of hypotheses and combine them for use. When we try to predict the target variable using any machine learning technique, the main causes of difference in actual and predicted values are noise, variance, and bias. Different ensemble models helps to reduce these factors.
Types
Below are the common ensemble methods:
-
Bagging
Bagging stands for bootstrap aggregation. Bagging uses bootstrap sampling to obtain the data subsets for training the base learners. For aggregating the outputs of base learners, bagging uses voting for classification and averaging for regression. Below is a simple diagram which explains the general idea behind bagging:
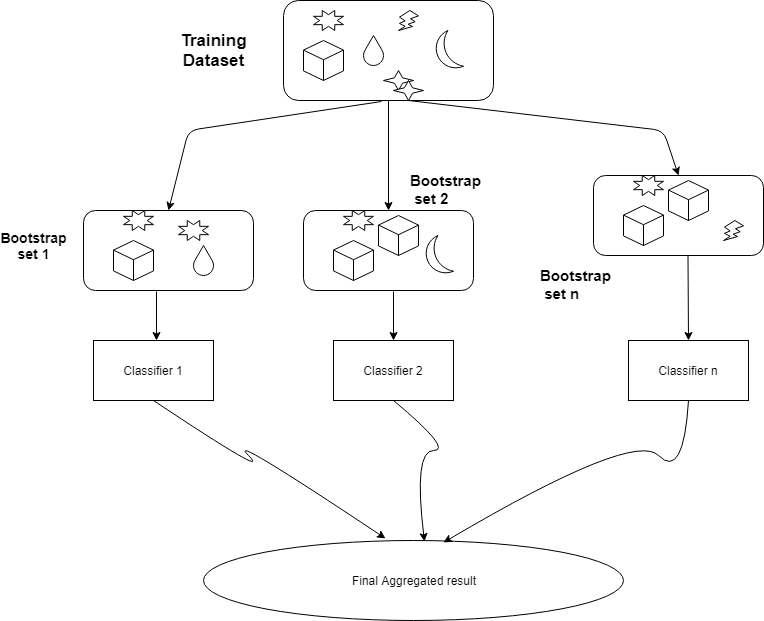
A commonly used class of ensemble algorithms are forests of randomized trees. In random forests, each tree in the ensemble is built from a sample drawn with replacement (i.e. a bootstrap sample) from the training set. In addition, instead of using all the features, a random subset of features is selected, further randomizing the tree.
-
Boosting
While bagging is a train and keep method, Boosting is a train and evaluate method. Boosting is an iterative technique which adjust the weight of an observation based on the last output. If an observation was classified incorrectly in an iteration, it tries to increase the weight of this observation in the next iteration or vice versa. However, they may sometimes over fit on the training data. Common algorithms in this type are Adaptive boosting techniques (Adaboost) and Extreme Gradient Boosting (XGBoost).
-
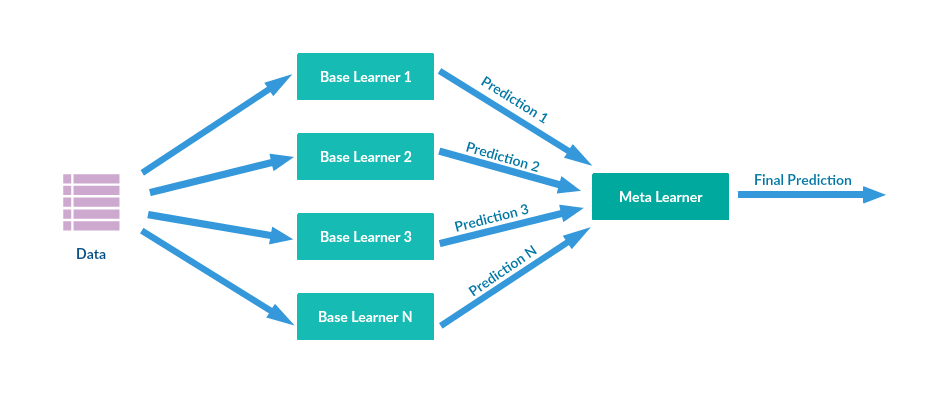
Stacking
Stacking is another ensemble model, where a new model is trained from the combined predictions of two (or more) previous model.
The predictions from the models are used as inputs for each sequential layer, and combined to form a new set of predictions. These can be used on additional layers, or the process can stop here with a final result.
Applications
Ensemble based systems can be also be useful when dealing with humongous amount of data or too little data. Consider the case of small datasets. In this case, bootstrapping can be helpful to train separate models using separate bootstrap samples of the data. Bootstrap samples are random samples of the data drawn with replacement and treated as if they are independently drawn from the underlying distribution. In contrast, the whole dataset can be partitioned into smaller subsets of data when there are so many training data points that making a single model for training is difficult and error prone. Under the constraints of some combinatorial rules, different models can be combined which were trained on each partition of the dataset. Other than improving the generalization performance of a classifier, they are used for
- Incremental learning: Incremental learning is the ability of a model to learn from new data that may become available after the model has already been generated from a previously available dataset.
- Decomposing a multi-class problem into several two-class problems
- Feature selection