
Relevant Text Extraction from PDFs
Data extraction for analysis can be as challenging as it is important to an organization with data available in sources of different sizes and formats. For this very purpose, we can use one of many techniques or multiple methods in combination to extract text and clean it, so as to make it as readable as possible to the end user. Natural language processing models are created on large chunks of text and for such models to perform well, it is important that this data makes sense and has little to no junk in it.
One of the many ways to read text from sources like PDFs is to directly decode and encode the text and extract it. Although, handling encodings like UTF-8, ASCII, Unicode, etc. can be challenging and it can result in loss of data. Another way is to scan and convert the sources into images and process them to extract text. This process is called Optical Character Recognition. This technique can be used on images as well as hand-written text. Also, if the text is computer typed, this method extracts text with a very high accuracy and at the same time there is no loss of data due to encoding. Through using this method, it is also possible to limit the number of pages to extract text from, which is useful when there is a need to avoid pages with no relevance.
All these techniques are not foolproof and even with the simplest of formats, there will be a lot of junk text that gets extracted along with the rest of the data. So it becomes imperative to further process text and remove text that does not make sense. This can be done through combining various techniques like natural language processing, pattern recognition, text transformations, entity recognition, etc.
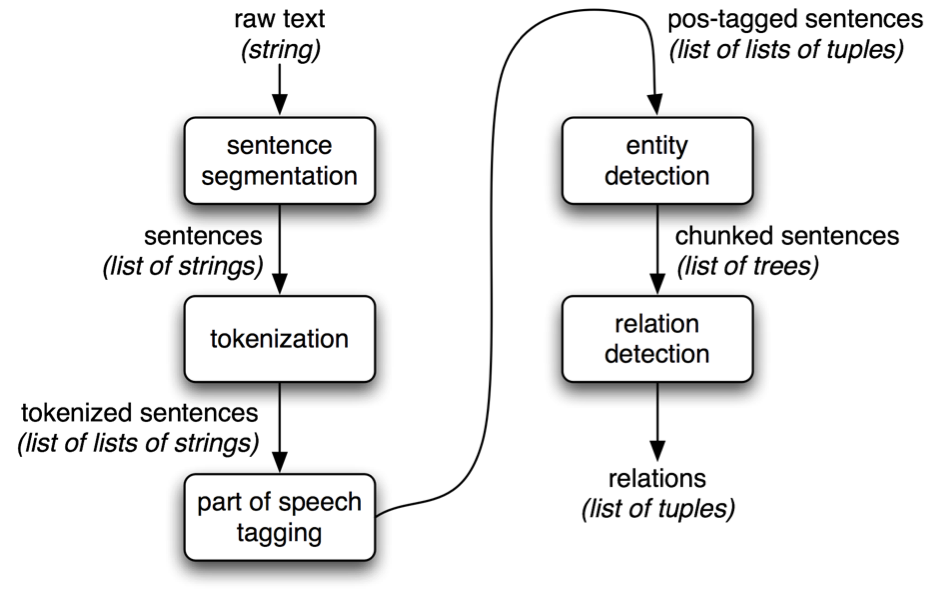
Natural language processing can be used to detect grammatical errors in text while also recognizing the part of speech. This gives context to the text and helps in keyword recognition. Another way of recognizing relevant text is by using stopwords to understand whether a word is a part of a sentence or not. NLP models are also used to predict the text that might follow a sequence of words and in doing so, these predictions can be used to distinguish relevant text from junk.
One of the biggest challenges in extracting relevant text is to remove junk elements like headers, footers, titles, text in figures and special characters like newline characters, etc. since all these elements are extracted as they get classified as text. A good way to handle these elements is by developing patterns that capture and remove them. Regular expressions enable the user to set up patterns in text and process the chunks of text that match the specified pattern. On matching the specified patterns, the user has the option to remove it, extract it or even replace it. This not only makes the whole process dynamic but also helps track patterns that might distinguish removable elements from the rest of the text.
An important feature of optical character recognition is that we can store the text as variables and then process these variables in isolation. This enables the user to process each page of text separately or even remove certain pages that have irrelevant information, like, prologues, disclaimers, etc.
A unique way to deal with all the complications that come along while extracting text is to build a corpus of relevant words and only extract words within the corpus. Word clouds can be created to analyze word frequency as well. Extracting relevant text has been an ongoing area of study and even now various techniques in deep learning are used to create personalized text extraction models that recognize and build a network of relevant patterns in text.
Follow