
Utilizing Large Language Models (LLMs) in enhancing Business Value
Introduction
This comprehensive article explores the transformative applications of Large Language Models (LLMs) in the realms of text summarization, language enhancement, and structured data analysis for businesses. We delve into how LLMs work, their practical usage, and their significance in summarizing content from PDF and HTML files. Additionally, we put LLMs in the context of structured data, such as CSV files and numerical data, and discuss frequently used LLMs and their capabilities.
The world of artificial intelligence has been revolutionized by Large Language Models (LLMs), which excel in understanding and generating human-like text. In this article, we examine how LLMs are reshaping text processing, language enhancement, and data analysis in business contexts. LLMs are founded on deep learning architectures, with GPT-3 being a standout example. These models are trained on vast datasets, enabling them to understand patterns, grammar, and context. GPT-3, with its 175 billion parameters, is particularly adept at generating coherent and contextually relevant text.
Use Cases:
Some of the most popular use cases for LLMs are:
Improving Clarity and Coherence: LLMs can refine text to improve clarity and coherence, making complex data accessible to a broader audience, including non-experts.
Customizing Tone and Style: LLMs adapt to create content in specific tones and styles, maintaining brand identity in business communication.
Multilingual Support: For global businesses, LLMs facilitate multilingual communication by translating and creating content in various languages.
PDF & HTML Summarization: LLMs, like GPT-3, are proficient in parsing PDF documents and generating concise summaries. This is invaluable in industries heavily reliant on PDF reports, such as law, finance, and research. LLMs also excel in summarizing content from HTML files, facilitating market research, competitive analysis, and news aggregation. The ability to swiftly distill web information enhances data-driven decision-making.
Enhancing Language for Business Insights: LLMs are not only skilled at summarization but also at enhancing the language and quality of business insights, ensuring coherent and engaging communication.
Structured Data Analysis with LLMs: While LLMs are primarily recognized for their text processing capabilities, they can also be effectively harnessed for structured data analysis. Structured data, often found in formats like CSV files, numerical datasets, and spreadsheets, represents a significant portion of the business world’s information. LLMs bring their transformative abilities to this domain, opening up new avenues for data-driven decision-making.
Data Summarization: Structured data often comprises vast amounts of numerical values and categorical variables. LLMs can be employed to extract meaningful insights from these datasets by generating concise summaries. For instance, when dealing with a large financial dataset, LLMs can automatically summarize key performance indicators, trends, or outliers, reducing the need for manual data analysis. This accelerates the decision-making process and ensures that critical insights are not buried in overwhelming volumes of data.
Natural Language Interfaces for Data Queries: LLMs offer the potential to bridge the gap between data analysts and non-technical business professionals. Natural language interfaces powered by LLMs enable users to pose data-related questions in plain language. The models understand the queries and retrieve relevant data, enabling users to gain insights without the need for specialized data analysis tools or technical expertise. This democratizes data access and empowers a broader range of stakeholders within an organization to make informed decisions.
Data Generation for Predictive Analysis: LLMs can also play a vital role in predictive analysis by generating synthetic data for training and testing machine learning models. For example, in scenarios where data privacy or data availability is a concern, LLMs can be used to generate synthetic datasets that closely resemble the original data’s statistical characteristics. This synthetic data can then be used to develop and fine-tune predictive models without compromising sensitive information.
In summary, the integration of LLMs into structured data analysis provides a powerful toolset for organizations looking to unlock the potential of their data assets. By automating data summarization, creating natural language interfaces, and generating synthetic datasets, LLMs facilitate more efficient and accessible data-driven decision-making. However, it’s important to keep in mind the need for appropriate data privacy and ethical considerations when applying LLMs to structured data, as well as the ongoing need for human expertise to interpret and act on the insights derived from these models.
Frequently Used LLMs:
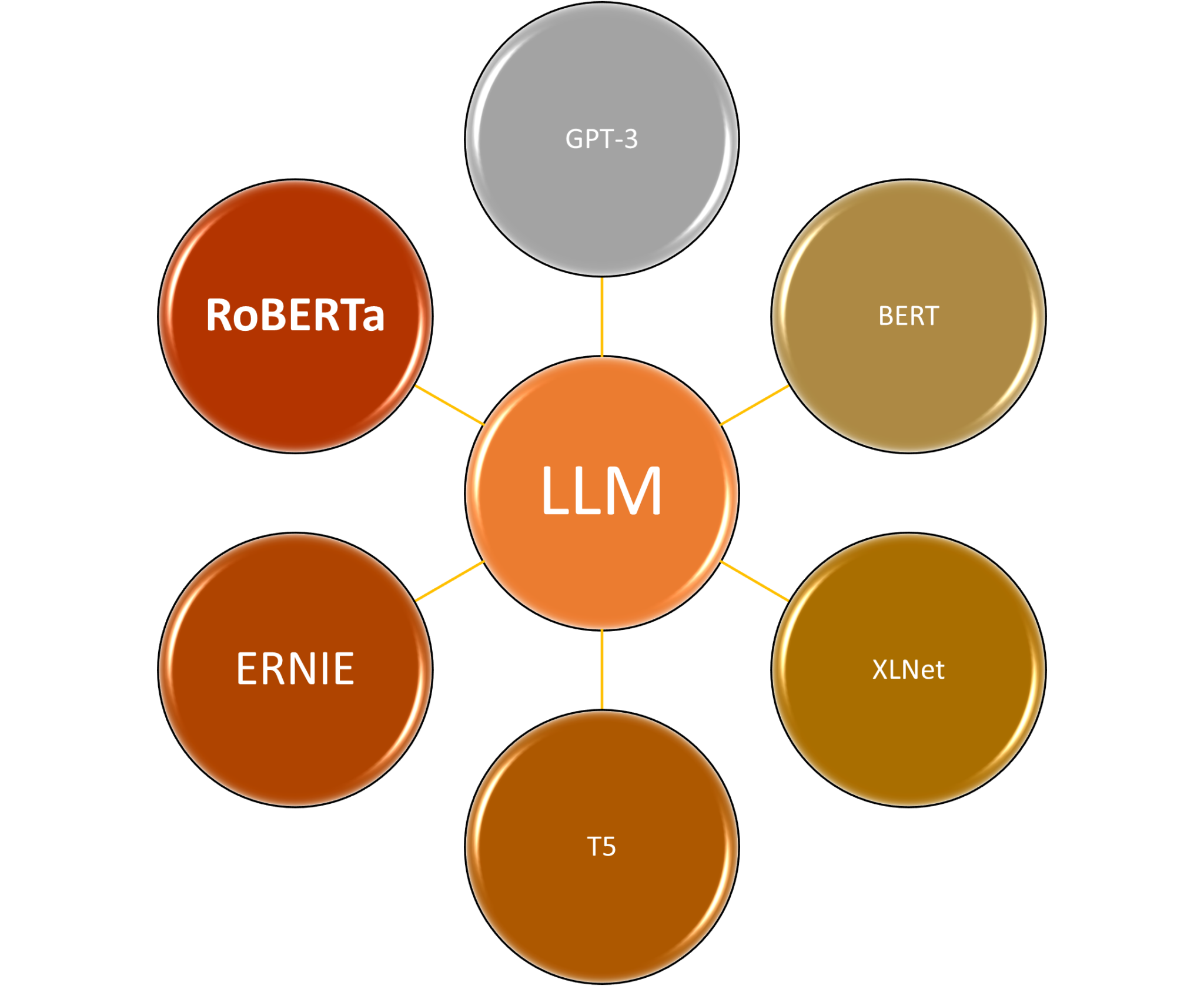
The landscape of Large Language Models is rich and diverse, with each model offering unique strengths and capabilities. Here, we provide more in-depth information about frequently used LLMs:
GPT-3 (Generative Pre-trained Transformer 3): GPT-3, developed by OpenAI, is one of the most prominent and influential LLMs to date. It boasts a staggering 175 billion parameters, making it one of the largest language models in existence. GPT-3 has shown exceptional performance in a wide range of natural language processing tasks, including text generation, translation, summarization, and even answering questions. What sets GPT-3 apart is its ability to produce coherent and contextually relevant text that closely mimics human language. Its versatility has made it a top choice for various applications, from chatbots to content generation, and it has significantly advanced the field of natural language understanding and generation.
BERT (Bidirectional Encoder Representations from Transformers): BERT, developed by Google, is renowned for its bidirectional approach to natural language understanding. Unlike previous models that read text in one direction, BERT processes text in both directions, allowing it to grasp the context and meaning of words based on their surrounding words. This innovative approach has led to outstanding performance in tasks like text classification, question answering, and language understanding. BERT’s pre-training on vast textual corpora equips it with a deep understanding of language, making it a valuable asset for applications that require context-aware interpretation of text.
6T5 (Text-to-Text Transfer Transformer): T5 takes a unique “text-to-text” approach to language understanding and generation. It views all language tasks as converting input text into output text. This unified framework has the advantage of simplicity and versatility. T5 is highly customizable, as it can be fine-tuned for specific NLP tasks by simply adjusting the input and output format. This flexibility has made T5 a favored choice for various applications, including translation, summarization, and text classification. Its adaptability to different tasks and its consistent architecture contribute to its appeal in the NLP community.
XLNet (Transformer-XL Network): XLNet is recognized for its ability to handle sequential data with sophistication. It employs a permutation-based training approach, allowing it to learn from all possible permutations of the input data. This approach enables XLNet to capture dependencies and relationships in sequential data more effectively. It has demonstrated remarkable performance in various language-related tasks, such as text classification, sentiment analysis, and sequence generation. Its strength in handling sequential data makes it a suitable choice for applications involving time series data, linguistic modeling, and beyond.
RoBERTa (A Robustly Optimized BERT Pretraining Approach): RoBERTa is an optimized version of BERT that addresses some of its limitations. By fine-tuning BERT’s training process and hyperparameters, RoBERTa achieves even better performance on various NLP benchmarks. It has become a popular choice for text understanding tasks and has been adopted by researchers and practitioners for its robustness and efficiency.
ERNIE (Enhanced Representation through kNowledge IntEgration): ERNIE, developed by Baidu, is designed to integrate external knowledge into language models. By incorporating knowledge graphs and external data sources, ERNIE enhances its language understanding and generation capabilities. This makes it particularly useful in applications that require domain-specific knowledge or understanding of specialized subjects.
Anthropic: Anthropic, an organization dedicated to developing advanced artificial intelligence models, has made notable contributions to the field of Large Language Models. While their LLM may not be as well-known as some of the earlier models, it is gaining attention for its unique capabilities. Anthropic’s LLM focuses on deep reinforcement learning and advanced natural language understanding, enabling it to perform complex tasks that require a deep understanding of language and context. It has shown promise in applications like content generation, reinforcement learning, and conversational agents.
Anthropic’s LLM is particularly intriguing due to its emphasis on aligning AI systems with human values and ethical considerations, making it a valuable player in the quest for responsible AI. As AI continues to evolve, Anthropic’s contributions to LLM technology showcase the ongoing innovation in the field and the importance of considering ethical and value-aligned AI development.
Conclusion:
The landscape of Large Language Models is rich and diverse, with each model offering unique strengths and capabilities. As businesses and researchers continue to explore the potential of LLMs in various applications, understanding the strengths and weaknesses of each model is essential for making informed choices. Whether it’s the massive scale of GPT-3, the bidirectional prowess of BERT, the flexibility of T5, the sequential data handling of XLNet, the optimization of RoBERTa, or the knowledge integration of ERNIE, LLMs are revolutionizing the field of natural language processing and data analysis, offering powerful tools to unlock the full potential of language and data in the business world. In an era marked by data-driven decision-making, LLMs are poised to revolutionize how information is extracted, processed, and communicated in the business world, empowering professionals to harness the power of language and data in more profound ways than ever before.