
Experiential Learning: Cross Sell Consumer Loans to Wealth Customers
Background & Objective
Wealth management companies usually provide all kind of investment, Insurance and lending solutions to their customers. Wealth Customers usually invest in savings instruments like Mutual Funds, Equities, Debt, Structured Products and buy Insurance of various kinds for protection.
Targeting Wealth customers for consumer loans offers numerous advantages for Institutions, including higher loan sizes, reduced credit risk, long-term customer relationships, upselling opportunities, reputation building, and market differentiation. One can identify lending customers from any pool of customer data through Machine Learning techniques to do consumer loans targeting. One of the projects we did was to identify the high propensity consumer loan target customers from the overall wealth base and secondly identify target Lending products from a large pool of customers.
Approach
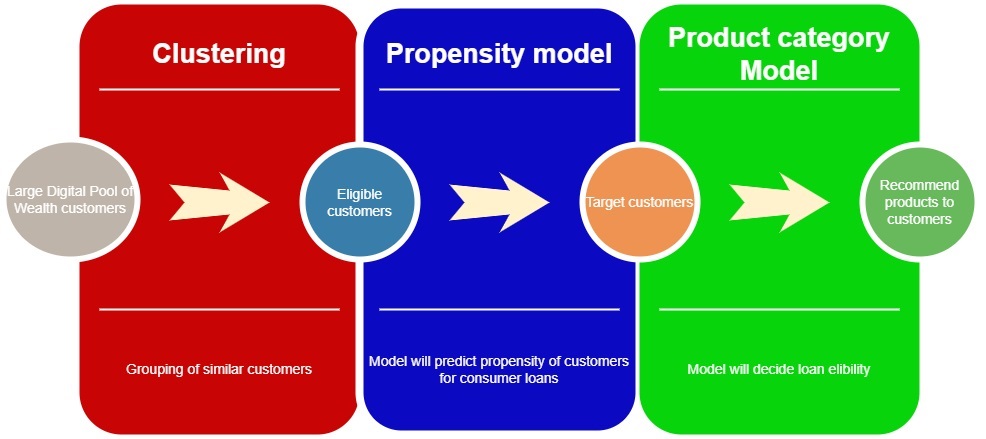
- Clustering:
We used the entire Wealth data, which we combined with consumer loans data for analysis. Initially, we focused on analyzing customer demographics data and transactional data. However, due to the high dimensionality of the Wealth data, extracting meaningful insights and achieving efficient analysis became challenging. To overcome this challenge, we employed Principal Component Analysis (PCA) to reduce the dimensionality of the data.
Since the number of consumer loans was significantly lower compared to the wealth data, our traditional approach of using machine learning models for cross-selling was not applicable. Instead, we opted for clustering analysis to group customers with similar characteristics and behaviors together. In this analysis, we excluded inactive old customers and new customers to ensure we had a relatively comparable pool of wealth data that aligned with the consumer loans data.
2. Propensity modeling:
We developed propensity model to predict customers that are most likely to be the consumer loan customers. We got a Gini of 56% which is for an imbalanced data like we had, is good enough to go ahead. After analyzing statistical metrics like specificity and sensitivity we decided on an appropriate cutoff. The customers having propensity more than cutoff were our target customers.
3. Product category model:
For product identification we build machine learning models taking consumer loan amount into consideration. So, our model will predict the eligibility loan amount for all the target customers from propensity model. Using product price and loan amount we offered products for each target customer.
We developed multiple models, including decision trees, random forest classifiers, and XGBoost classifiers, for propensity modeling. To assess their performance, we evaluated various metrics such as precision, Gini coefficient, AUC (Area Under the Curve), ROC (Receiver Operating Characteristic) curve, accuracy, sensitivity, and specificity.
In the case of the product category model, we explored several approaches, including linear regression and complex regression tree models. However, after careful evaluation, we found that the regression model from stats models provided the best results. Consequently, we decided to proceed with this model for our analysis.
Outcome
We developed a propensity model to predict customers that are most likely to be the consumer loan customers. The customers having propensity more than cutoff were our target customers.
Using the selected regression model, we predicted the loan amount for each of our target customers. We then employed a simple bucketing technique to group product prices and loan amounts. This allowed us to recommend specific products for each of our target customers based on their loan amount.
By leveraging these modeling techniques and the subsequent recommendations, we can effectively tailor our offerings to individual target customers. This approach maximizes the relevance and personalization of our product recommendations, enhancing customer satisfaction and increasing the likelihood of loan acceptance.
Follow