
Introduction:
Credit risk modeling has evolved significantly over the years. Traditional Probability of Default (PD) models relied heavily on historical default experience across risk segments. However, with regulatory and accounting requirements increasingly demanding forward-looking risk assessment, incorporating macroeconomic information into PD estimation has become essential.
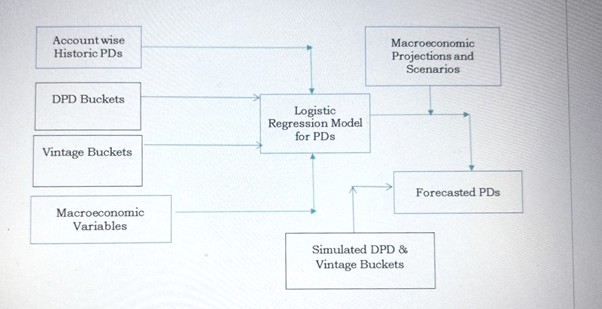
In this blog, we walk through our approach to building an account-level Point-in-Time (PIT) PD model driven by macroeconomic variables using logistic regression.
Why Move from Segment-Level to Account-Level PD?:
Earlier frameworks linked aggregated PDs to macroeconomic variables to capture economic sensitivity. While effective at a portfolio level, they lacked granularity.
The enhanced framework:
- Models PD at the individual account level
- Incorporates macroeconomic sensitivity
- Generates quarterly forward-looking PD projections
- Enables more precise credit risk monitoring and accounting alignment.
- Explicitly incorporates DPD buckets and Vintage buckets in the modelling framework.
This approach bridges historical credit performance with projected economic conditions.
Selecting the Right Macroeconomic Drivers:
We began by identifying macroeconomic variables that capture economic growth, credit expansion, inflation, wage trends, and fiscal position.
Macroeconomic Variables Considered
- Nominal GDP
- Real GDP
- Real GVA
- Real Agriculture, Industry, Services
- Nominal GVA (sector-wise)
- Total Bank Credit
- Food & Non-Food Credit
- CPI
- Rural Wage Growth
- Gross Tax
- Total Expenditure
These variables help capture both demand-side and supply-side economic dynamics affecting borrower repayment capacity.
Data Transformation & Feature Engineering:
Macroeconomic time series often suffer from scale differences, trends, and multicollinearity. To ensure model stability:
1. Multicollinearity Check
- Variance Inflation Factor (VIF) was used.
- Highly collinear variables were excluded.
2. Transformations Applied
- Natural log transformation (to normalize distributions)
- Standardization (to ensure comparability)
3. COVID Moratorium Adjustment
Data from 2020Q1 to 2021Q1 was excluded due to regulatory moratorium distortions. This ensured that temporary relief measures did not bias the structural macro–PD relationship.
4. Statistical Screening
Variables were shortlisted based on:
- Correlation with historical PD
- Statistical significance
- Predictive power
- Economic intuition
- Stability across time
4. Dummy Variables of DPD & Vintage Buckets
DPD buckets and Vintage buckets are converted into dummy variables to systematically incorporate delinquency stages and loan seasoning effects into the regression framework. The model estimates separate coefficients for each bucket, allowing us to quantify their impact on default risk. This ultimately enables projection of bucket-wise PDs using the learned coefficients.
Constructing the Account-Level Modeling Dataset:
The modeling base was built using two core datasets:
Loan Details Dataset (Static/Semi-Static Information)
- Agreement ID
- Interest Start Date
- Agreement Status
- System Closing Date
- Product & Scheme Classification
- Original Tenor
- Customer Category
Monthly Loan Tape (Dynamic Performance Data)
- Principal Outstanding (POS)
- Adjusted DPD
- Interest Rate
Quarterly Aggregation
To align with macroeconomic data:
- Monthly data was aggregated to quarterly frequency
- Maximum adjusted DPD within a quarter was used (worst delinquency capture)
Default Definition (PIT Framework)
For each account-quarter observation:
- Default = 1 if account transitions to 90+ DPD within next 4 quarters
- Otherwise, Default = 0
This creates a forward-looking, one-year PIT default indicator.
Vintage Calculation
Vintage was computed as:
Days between Interest start date & reporting date.
Closed accounts were adjusted using system closing dates.
The final dataset contains:
- Account-level attributes
- Quarterly performance indicators
- Vintage
- Forward default outcome
- Aligned macro variables
Logistic Regression for PD Estimation:
We used Logistic Regression as the core modeling technique due to:
- Interpretability
- Regulatory acceptance
- Stable probability outputs
- Transparency of macro sensitivity
The model estimates PD as:
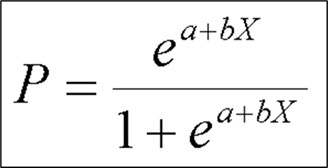
Variable Selection Criteria
- Statistical significance
- Predictive power
- Economic rationale
- Lead/lag relevance
- Stability across time
Model Performance Evaluation:
Model discrimination was evaluated using:
- AUC (Area Under ROC Curve)
- Gini Coefficient
- KS Statistic
These metrics assess how well the model distinguishes between defaulting and non-defaulting accounts.
Generating Forward-Looking PDs:
Once the macro-PD relationship was established:
- Macroeconomic variables were projected using:
- Statistical forecasting methods
- Economist scenario inputs
All possible DPD buckets and Vintage buckets were simulated within the projection framework to generate bucket-wise forward-looking PD estimates.
Key Learnings:
- Account-level modelling significantly enhances risk sensitivity by capturing DPD and vintage effects alongside macroeconomic dynamics.
- Clean separation between data preparation, feature engineering (macro + bucket dummies), and model estimation improves transparency and auditability.
- Statistical modelling techniques (Logistic Regression, feature transformation, scenario simulation) become far more powerful when combined with domain understanding of credit behaviour.
- Moving from aggregate segment-level PDs to account-level frameworks does not just improve granularity it enables bucket-wise PD estimation and deeper behavioural insights.
Conclusion:
Credit risk modelling is evolving toward greater granularity and forward-looking intelligence.
As risk practitioners and data scientists, our role is not just to estimate PDs, but to design frameworks that capture behavioural stages, seasoning effects, and macroeconomic sensitivity in a unified structure.
By transitioning from aggregate PD approaches to account-level macro-integrated modelling, institutions can achieve more accurate, interpretable, and scenario-sensitive PD estimates strengthening provisioning, monitoring, and strategic risk management.
Follow