Moving compute to data using MonetDB
With the advent of big data, today, it is very common to encounter cases where the data is too large to fit in the memory; it is still small for hard disk storage but can easily reach the limit of RAM. Solutions to this problem include querying the data from the database using MySQL etc. to perform operations. Even the style in which the data is stored in the database impacts the processing speed depending on the use-cases. MySQL and other relational databases are examples of row-store databases where the data is stored tuple by tuple. Row stores are great for transaction processing but not so great for highly analytical query models, which is where another data storage model, column-store is useful. Here, the data is stored column by column. A column store is awesome at aggregating large volumes of data for a subset of columns with very fast query speeds.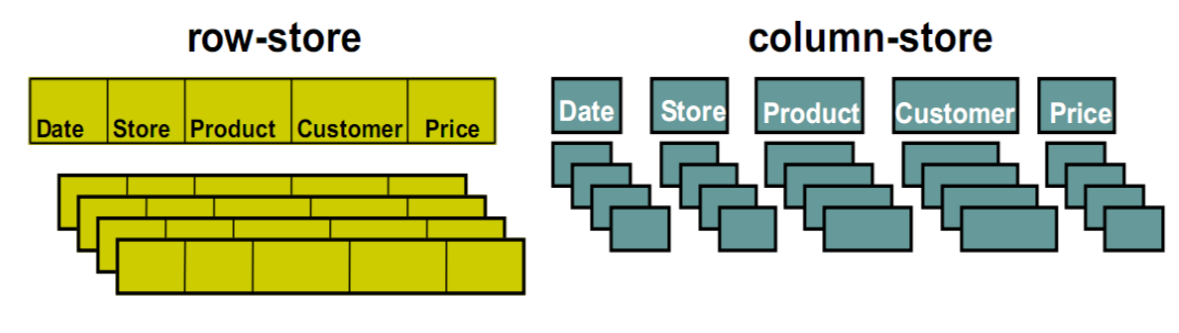
Pertaining to these advantages, we are trying to build machine learning algorithms by querying the tables/datasets in MonetDB. This will totally eliminate the need to store the huge datasets inside the memory which is what most data scientists/analysts usually do while using R/Pandas dataframes to perform analytics on the data. This eats up a lot of memory space. We have developed a wrapper around MonetDB to give a consistent interface to analytical queries which we are using to build ML algorithms like linear regression and decision trees. One thing to keep in mind is the idea of lazy evaluation which means, the mapping and computation of the column stores for conversion to a dataframe like object is delayed until needed. All sorts of aggregation/computation queries are stored in the object and evaluated only when explicitly asked. MonetDB facilitates some statistical functions in its queries like mean, standard deviation, correlation and quantile. We made use of these to write our own code for linear regression which can also take categorical attributes as explanatory variables and use the corresponding transformed dummy variables along with other numerical attributes to build a linear regression model. Everything was done without storing even a single dataset column (with all the observations) in the main memory.
As mentioned earlier, the aggregation operations are very fast in column-store databases. These functions formed the crux for the splitting computations in our decision trees algorithm which is currently at development stage. Again, all the calculations from the information theory including entropy and information gain are being done outside the memory.
Some core functions we built:
- Compute: This function evaluates the full dataframe as per the query and returns a pandas dataframe. This function is called after all the operations on the dataframe have been coded in the query.
- Filter: This function builds a query which subsets the dataset based on single or multiple logical conditions.
- Agg: This function aggregates the values of a particular column based on a given function: max, min, average or sum
- Groupby: This function, like in MySQL, groups the values of a column on different levels of another given column.
- Entropy: Using functions like the ones mentioned above, this function calculates the entropy given by the following formula. Here, c is unique number of categories in the dependent variable and pi is the fraction of values in the class i
This framework can be taken forward to develop more sophisticated machine learning algorithms which would run ‘out-of-the-core’ and we can work on them almost as if the data is stored in local variables.